by Antonin Duval
Artificial intelligence (AI) has now been in embryology for more than 5 years, with a particular focus on embryo evaluation.
You may have wondered, however, how AI is actually able to “see” an embryo. How does it learn, for example, that a specific arrangement of cells could be associated with a poor-quality embryo?
While we at ImVitro strongly believe that AI is here to stay, we also understand that this is a new technology that embryologists will want to understand better before leaning on its recommendations. So let’s start with the basics: in this post, we will explore how a computer vision AI model is trained to “see” and how this is accomplished thanks to matrices and optimization.
Let’s get into it!
1- What is Computer Vision?
a) What is an image?
Before delving into computer vision, it is important to understand what a computer registers as an image. Just as you have eyes that perceive color through photoreceptor cells that convert light into electrical signals, a computer has its own way of registering images.
When a computer perceives an image, it interprets the image as a grid of tiny elements called pixels. Each pixel represents a discrete point in the image and contains information about the pixel’s intensity. In the case of a gray image, the pixel is made up of one value, comprised between 0 and 255.
The entire image is therefore a matrix, where each element corresponds to a specific location and holds numerical values that represent the intensity at that point.
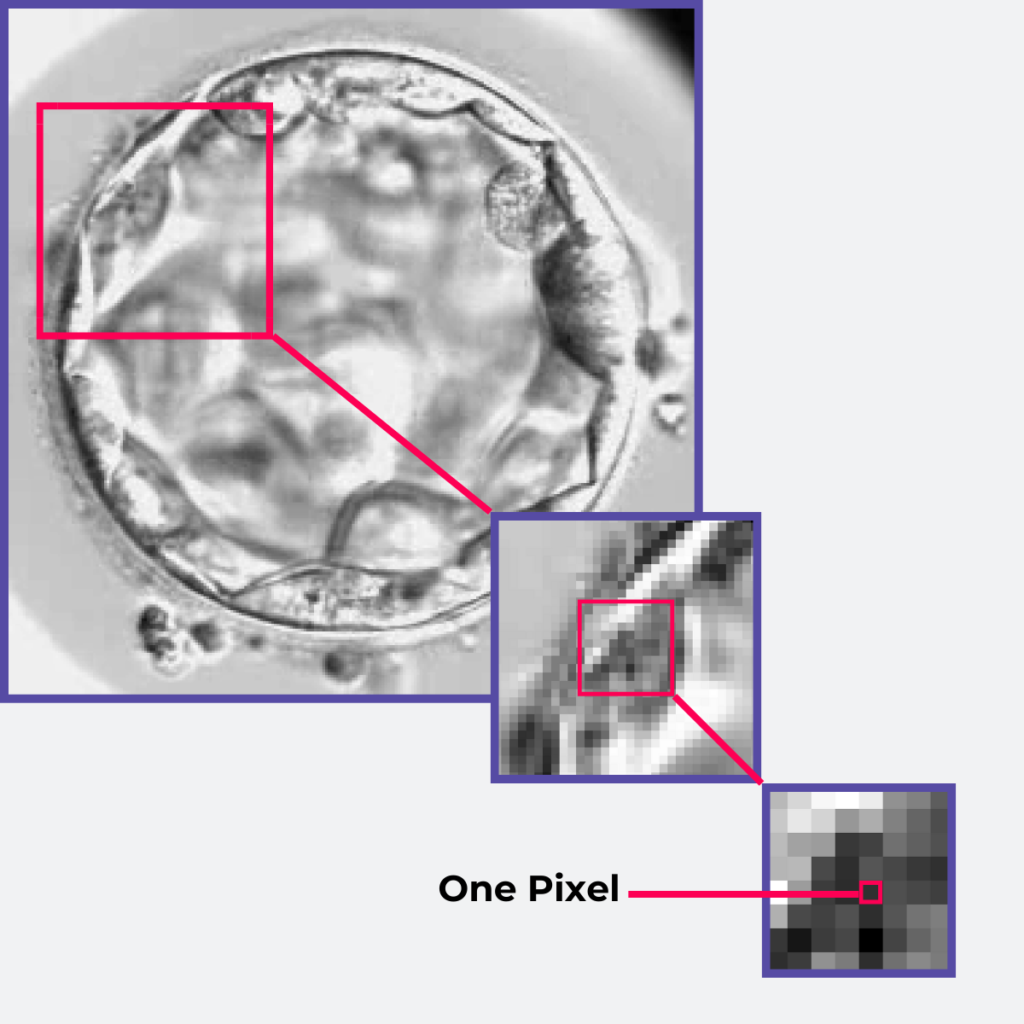
Example of an image of an embryo in grayscale. Each pixel in the embryo is associated with a value which represents the intensity. The closer it is to 255, the more white it is; the closer to 0, the darker.
Computers can process any images or videos (which are, after all, a series of pictures) using matrices. Over the years, researchers in computer science have found that they could use properties of a matrix to extract information (shapes, textures, edge detection, etc.) from the image. Those methods operating on an array of pixels are grouped in the field called Computer Vision.
b) What is Computer Vision?
Computer vision can be described as finding features from images to help discriminate objects and/or classes of objects.
From 1960 until 2012, researchers relied mostly on what we call traditional computer vision methods, which involve using rules defined by humans to identify features.
For instance, edge detection algorithms identify edges defined as rapid changes in pixel intensity, revealing the contours of objects.
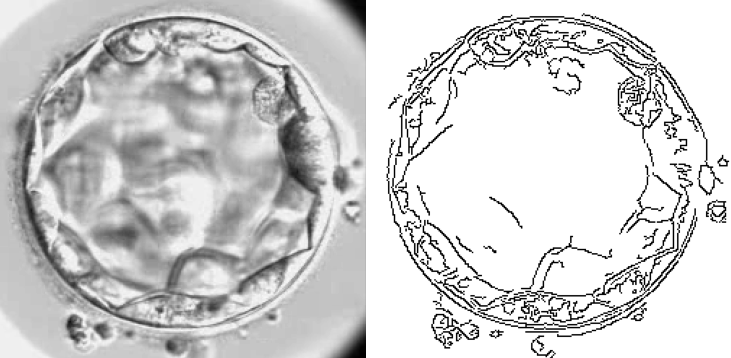
Edge detection algorithm: an example of a traditional computer vision method
However, the downside to these traditional methods is that they don’t adapt well to various scenarios and situations. They also require a lot of human expertise and intervention in selecting and creating relevant rules based on domain knowledge, which can be time-consuming. Embryo images can also vary significantly due to differences in image acquisition settings between microscopes or because of their diverse shapes.
This is where AI based on convolution comes in.
2- How does a deep learning model “see”?
a) The magic of convolution
One mathematical operation often used in traditional computer vision is called convolution. This operation involves applying filters (also called kernels) to an image in order to extract features like edges, textures, and shapes.
This filter is a small matrix of parameters. It “slides” over the image pixel by pixel, at each step performing an elementwise multiplication with all nearby pixels and then summing up each product into a single output pixel. The filter performs this operation for each location it slides over, resulting in a new array of pixels which is called a feature.
Basic example of a convolution applied to an image. On a real image, instead of having 0 and 1, you would have values between 0 and 255.
The filters can perform various operations, such as edge detection, blurring, sharpening, etc. depending on the parameters inside. Current Computer Vision AI models, like the one used at ImVitro, are composed of many convolution filters applied sequentially. Those models are called Convolutional Neural Networks (CNN).
Contrary to traditional computer vision methods, the parameters in the filters of a CNN are not manually designed by an expert; instead, they are learned by the algorithm during the training process, through trial and error.
So, how do we teach an AI so its convolution filters are tailored to extract task-relevant features?
3- Learning to extract smart features
Let’s take the example of an AI model applied to embryos where we want to train an AI model to detect whether a blastocyst will lead to a pregnancy or not.
In this specific case, the AI model has to learn features that are relevant for an embryo, so textures and shapes are linked to the quality of the blastocyst. To do that, it must adapt the parameters of the convolution filters.
We gathered a dataset with images of transferred blastocysts for which we know the pregnancy outcome. To train the CNN model, we give it a large volume of images, each labeled with the output we want to predict (e.g. pregnancy or not). The model then applies multiple convolutions to each image, learning to associate certain visual features with the labeled output. At the end of the model, we get a final prediction value between 0 (no pregnancy predicted) and 1 (pregnancy predicted).
The goal of the training is to minimize the difference between the model’s predictions and the actual labels by adjusting the parameters inside the filters applied during the convolutions. This process, called “backpropagation“, continues iteratively until the model’s predictions reach an acceptable level of accuracy.
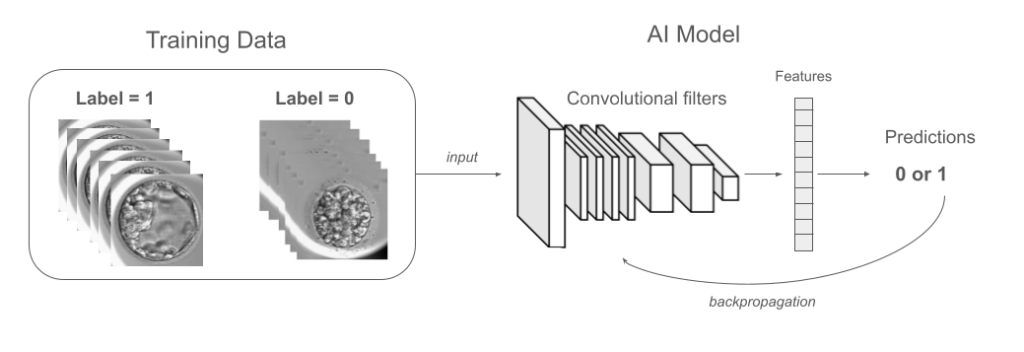
Example of a training flow. Images are fed to the model during training. The convolutions filters extract features from the image and output a predicted label (0 or 1) accordingly. The prediction is compared to the actual label of the image, and the parameters of the convolution filters are updated thanks to the backpropagation to reduce the error. This process is repeated multiple time until optimal performance are achieved.
Little by little, the features extracted by the convolutional filter will start to be more and more relevant, and the accuracy of the model will increase.
This can be compared to the way our brain works, where we adapt our knowledge through examples and errors. The CNN model does the same by changing the features it extracts to maximize the accuracy.
4- Tasks a CNN can solve
As you now understand, CNN models are versatile and can be applied to various image modalities, including X-rays, MRI, CT, pathology slides, and, of course, time-lapse videos of embryos.
Indeed, CNN models can be trained to solve a variety of tasks in embryology:
- Object detection: Finding an object in an image (e.g. number of pronuclei in an embryo).
- Object segmentation: Delineating the boundary of an object in an image (e.g. segmenting the embryo from the background).
- Classification: Categorizing an object in an image (e.g. grading the quality of an embryo).
- Tracking: Following the movement or development of an object (e.g. tracking the growth of an embryo over time).
- Generation: Creating new images or modifying existing ones. This type of task has seen less popularity in embryology as the applications of image generation are still being explored.
Conclusion
We hope this blog post helped you understand how a computer can see!
The world of computer vision offers an exciting frontier for embryology, with the potential to revolutionize how we approach everything from embryo grading to predicting pregnancy outcomes.
By harnessing the power of AI and deep learning, we can uncover insights hidden deep within your data to become a second pair of eyes in the lab and push the boundaries of what is possible in reproductive medicine.
If you are interested in learning more, you can read our other blog post that delves further into the realm of AI algorithms for embryo evaluation! In a future post, we will cover how an AI model can learn features from a video that are time-dependent.